由于本人之前没有接触过python和机器学习的相关知识,这次图像分类的配置过程可谓一路艰辛,本文当是一次避坑总结。
配置环境概览:
平台: Windows 11
一、环境安装
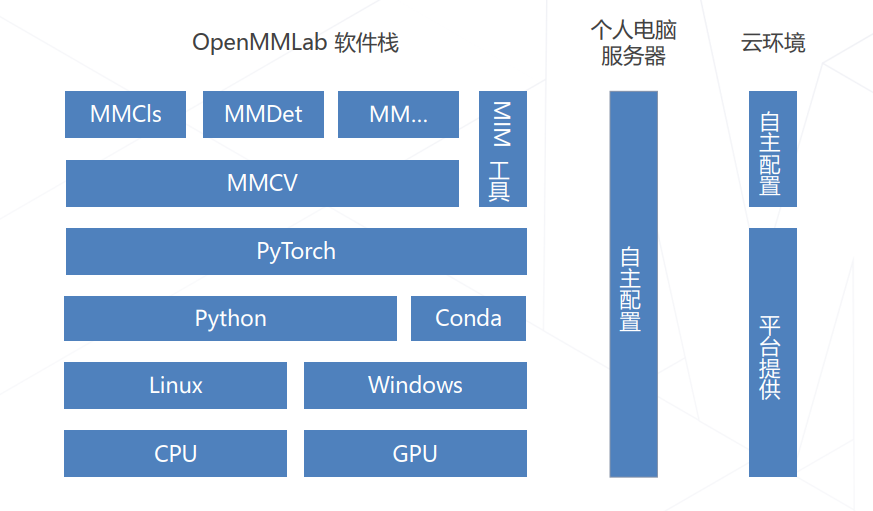
整体环境框架如下:
1. CUDA 与 cuDNN 安装
网上有很多的教程,这里就不再赘述了,不过我以后有时间会补充上滴。这里推荐一个:【CUDA】cuda安装 。
2. ANACONDA 环境与 Pycharm 配置
2.1 ANACONDA 安装
ANACONDA(conda)不仅自带了许多 Python 的包,同时可以创建 Python 虚拟环境,与系统自身的环境相隔离,方便一大堆包的管理。这里参考 anaconda安装超详细版 。
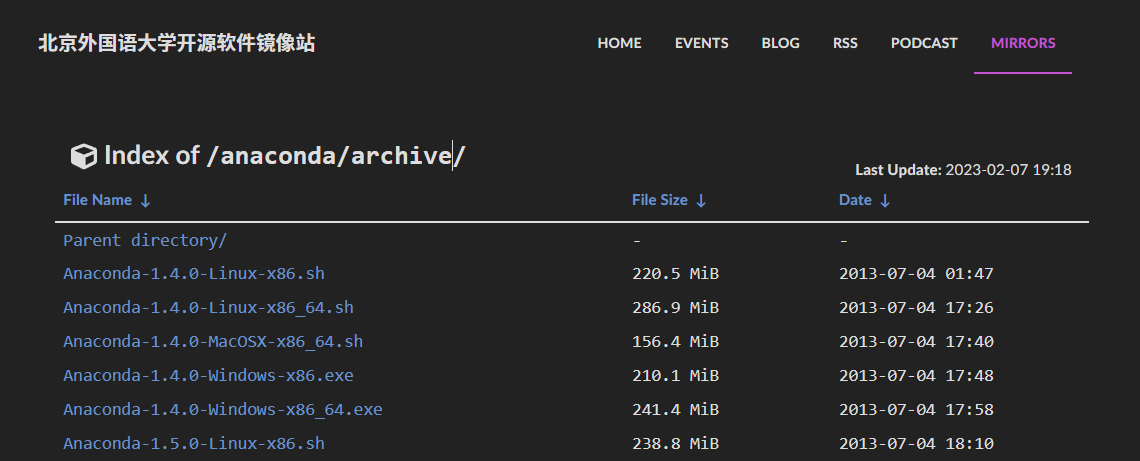
下载:官网 镜像站 (速度快,推荐,如下图)
安装:exe —— Next —— Next —— 选择一个合适的安装路径 — Next —— 全选(添加 conda 到环境变量中),Install —— Next —— 两个√去掉 —— Finish
检验安装:python ,回车,查看是否有 Python 环境,若显示 Python 3.9.16 就说明OK。conda --version ,回车,查看 conda 是否成功安装,若显示 conda 22.9.0 就说明OK。
更换 conda 源(加快第三方库的安装速度)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --set show_channel_urls yes
查看是否已更改下载源:
conda config --show channels
创建虚拟环境:
# 查看已有虚拟环境: conda env list conda info -e # 创建虚拟环境 conda create -n env_name python=x.x # 激活虚拟环境 activate env_name # 删除虚拟环境 conda remove -n env_name --all # 切换回默认环境 deactivate env_name activate base activate
比如我创建虚拟环境为:conda create -n pytorch_env python=3.9 。过程中会让你输入y 进行确认。Open SSL 官网 下载相应版本的软件,安装过程中勾选 “The Windows system directory”。但是我电脑因为系统保护等原因还是不行,这时发现 conda 的安装目录 ANACODA\Library\bin\ 中有 openssl.exe 和 openssl.pdb 这两个文件,我把它们复制到 C:\Windows\System32\ 中,意外的就好了。
2.2 在 PyCharm 2022 中使用 conda 虚拟环境
可选操作,实际中大部分过程 PyCharm 只被我当作了 python 文件的编辑器,运行全在终端上完成。这个虚拟环境因为我老早之前就用上了,第一次怎么添加的我记不清了,不过我这里推荐一个博客:在pycharm中使用conda虚拟环境(conda虚拟环境是已经创建好的) 。
3. 第三方库安装
第三方库的安装必须要切换到对应的虚拟环境中去安装!后面对这些库的使用也要在该虚拟环境下进行!
3.1 Pytorch 安装
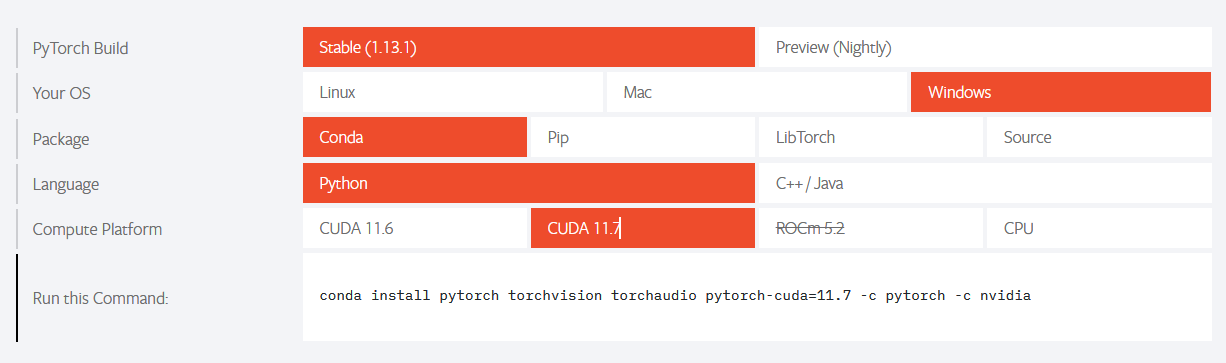
安装:官网 ,选择合适的版本:
检验安装:
python import torch torch.cuda.is_available()
若返回 true,就说明目前你所有操作都是正确的。
3.2 OpenMMLab 相关库安装
pip install -U openmim pip install openmim
安装 MMClassification
从源码安装(推荐):希望基于 MMClassification 框架开发自己的图像分类任务,需要添加新的功能,比如新的模型或是数据集,或者使用我们提供的各种工具。
作为 Python 包安装:只是希望调用 MMClassification 的 API 接口,或者在自己的项目中导入 MMClassification 中的模块。
git clone https://github.com/open-mmlab/mmclassification.git cd mmclassification pip install -v -e . # "-v" 表示输出更多安装相关的信息 # "-e" 表示以可编辑形式安装,这样可以在不重新安装的情况下,让本地修改直接生效
这个时候你的终端就进入了 mmclassification 文件目录中,不出意外,你可以在 C:\Users\User_name\ 中找到该文件夹。
mim download mmcls --config resnet50_8xb32_in1k --dest .
python demo/image_demo.py demo/demo.JPEG resnet50_8xb32_in1k.py resnet50_8xb32_in1k_20210831-ea4938fc.pth --device cpu
如果出现下图所示的结果,就表明配置工作已经全部结束,接下来就可以进行模型的训练了:
二、模型训练
2.1准备数据集
我的数据集是在网上下载的 flower 数据集 ,有 5 个文件夹,每个文件夹名对应一种花,分别为:daisy, dandelion, rose, sunflower, tulip, 每种花含有图片 500+ 张,而我们要将这个数据处理成 mmcls 能够处理的文件组织形式—— ImageNet:
flower_dataset |--- meta | |--- classmap.txt ——存放类与名称的对应关系 | |--- train.txt ——训练集文件信息 | |--- val.txt ——验证集文件信息 | |--- test.txt ——测试集文件信息 |--- train | |--- class1 ——某一种花的图片存放目录 | | |--- NAME1.jpg | | |--- ... | |--- class2 | | |--- NAME1.jpg | | |--- ... | |--- class3 | | |--- NAME1.jpg | | |--- ... | |--- class4 | | |--- NAME1.jpg | | |--- ... | |--- class5 | | |--- NAME1.jpg | | |--- ... |--- val | |--- class1 | | |--- NAME1.jpg | | |--- ... | |--- class2 | | |--- NAME1.jpg | | |--- ... | |--- class3 | | |--- NAME1.jpg | | |--- ... | |--- class4 | | |--- NAME1.jpg | | |--- ... | |--- class5 | | |--- NAME1.jpg | | |--- ... |--- test | |--- class1 | | |--- NAME1.jpg | | |--- ... | |--- class2 | | |--- NAME1.jpg | | |--- ... | |--- class3 | | |--- NAME1.jpg | | |--- ... | |--- class4 | | |--- NAME1.jpg | | |--- ... | |--- class5 | | |--- NAME1.jpg | | |--- ...
Ps:本次训练我没有用到测试集
Step 1.
Step 2.
class1 daisy 0 class2 dandelion 1 class3 rose 2 class4 sunflower 3 class5 tulip 4
向 train.txt 和 val.txt 文件中写入如下内容(test.txt 同理):
class1/A119.jpg 0 class1/A120.jpg 0 ...
当然,这个工作量太大了,我们不可能手写,这里我借用的是一位博主 何小义的AI进阶路 的程序:
import osimport globimport re''' 生成train.txt val.txt test.txt ''' root_dir = "/xxx/data/cats_dogs" train_dir = os.path.join(root_dir, "train" ) val_dir = os.path.join(root_dir, "val" ) test_dir = os.path.join(root_dir, "test" ) meta_dir = os.path.join(root_dir, "meta" ) def generate_txt (images_dir,map_dict ): imgs_dirs = glob.glob(images_dir+"/*/*" ) imgs_dirs = [ii.replace('\\' , '/' ) for ii in imgs_dirs] images_dir = images_dir.replace('\\' , '/' ) typename = images_dir.split("/" )[-1 ] target_txt_path = os.path.join(meta_dir, typename+".txt" ) f = open (target_txt_path, "w" ) for img_dir in imgs_dirs: filename = img_dir.split("/" )[-2 ] num = map_dict[filename] relate_name = re.findall(typename+"/([\w / - .]*)" ,img_dir) f.write(relate_name[0 ]+" " +num+"\n" ) def get_map_dict (): class_map_dict = {} with open (os.path.join(meta_dir, "classmap.txt" ),"r" ) as F: lines = F.readlines() for line in lines: line = line.split("\n" )[0 ] filename, cls, num = line.split(" " ) class_map_dict[filename] = num return class_map_dict if __name__ == '__main__' : class_map_dict = get_map_dict() generate_txt(images_dir=train_dir, map_dict=class_map_dict) generate_txt(images_dir=val_dir, map_dict=class_map_dict) generate_txt(images_dir=test_dir, map_dict=class_map_dict)
然后数据集可以放在任何你想放置的地方,不过我为了调用方便,将数据集专门放在了 *mmclassification\data* 文件夹中(要自己新建一个)。
2.1准备配置文件
配置文件结构
在 configs\base \ 文件夹下有 4 个基本组件类型,分别是:
模型( model )
数据( data )
训练策略( schedule )
运行设置( runtime )
在 configs\ 中其他的文件夹则是各训练模型总的配置文件,比如 configs\mobilenet_v2\mobilenet-v2_8xb32_in1k.py 中可以看到该模型的配置属性:
_base_ = [ '../_base_/models/mobilenet_v2_1x.py' , '../_base_/datasets/imagenet_bs32_pil_resize.py' , '../_base_/schedules/imagenet_bs256_epochstep.py' , '../_base_/default_runtime.py' ]
你可以选择任何合适的模型,我这里使用的是 resnet18b32x8 模型,因为我对 python 不熟,所以就按照官方的模板进行配置。
注册自己的数据集
新建 mmcls\datasets\flower_dataset.py ,建立自己的数据集定义脚本。
import numpy as npfrom .builder import DATASETSfrom .base_dataset import BaseDataset@DATASETS.register_module() class FlowerDatasets (BaseDataset ): CLASSES = ["daisy" , "dandelion" , "rose" , "sunflower" , "tulip" ] def load_annotations (self ): assert isinstance (self.ann_file, str ) data_infos = [] with open (self.ann_file) as f: samples = [x.strip().split(' ' ) for x in f.readlines()] for filename, gt_label in samples: info = {'img_prefix' : self.data_prefix, 'img_info' : {'filename' : filename}, 'gt_label' : np.array(gt_label, dtype=np.int64)} data_infos.append(info) return data_infos
在 mmcls\datasets\init .py 中添加自己定义的数据集,进行注册:
... from .flower_dataset import FlowerDatasets __all__ = [ 'BaseDataset' , 'ImageNet' , 'CIFAR10' , 'CIFAR100' , 'MNIST' , 'FashionMNIST' , 'VOC' , 'MultiLabelDataset' , 'build_dataloader' , 'build_dataset' , 'DistributedSampler' , 'ConcatDataset' , 'RepeatDataset' , 'ClassBalancedDataset' , 'DATASETS' , 'PIPELINES' , 'ImageNet21k' , 'SAMPLERS' , 'build_sampler' , 'RepeatAugSampler' , 'KFoldDataset' , 'CUB' , 'CustomDataset' , 'StanfordCars' , 'FlowerDatasets' ] ...
设置数据配置文件
新建 config\base \datasets\flower_dataset.py ,导入自己的数据,并进行相关操作。
dataset_type = 'FlowerDatasets' img_norm_cfg = dict ( mean=[123.675 , 116.28 , 103.53 ], std=[58.395 , 57.12 , 57.375 ], to_rgb=True ) train_pipeline = [ dict (type ='LoadImageFromFile' ), dict (type ='RandomResizedCrop' , size=224 ), dict (type ='RandomFlip' , flip_prob=0.5 , direction='horizontal' ), dict (type ='Normalize' , **img_norm_cfg), dict (type ='ImageToTensor' , keys=['img' ]), dict (type ='ToTensor' , keys=['gt_label' ]), dict (type ='Collect' , keys=['img' , 'gt_label' ]) ] test_pipeline = [ dict (type ='LoadImageFromFile' ), dict (type ='Resize' , size=(256 , -1 )), dict (type ='CenterCrop' , crop_size=224 ), dict (type ='Normalize' , **img_norm_cfg), dict (type ='ImageToTensor' , keys=['img' ]), dict (type ='Collect' , keys=['img' ]) ] data_root = '.../mmclassification/data/flower_dataset' data = dict ( samples_per_gpu=32 , workers_per_gpu=2 , train=dict ( type =dataset_type, data_prefix=data_root + '/train' , ann_file=data_root + '/meta/train.txt' , pipeline=train_pipeline), val=dict ( type =dataset_type, data_prefix=data_root + '/val' , ann_file=data_root + '/meta/val.txt' , pipeline=test_pipeline), test=dict ( type =dataset_type, data_prefix=data_root + '/val' , ann_file=data_root + '/meta/val.txt' , pipeline=test_pipeline ) ) evaluation = dict ( interval=1 , metric='accuracy' )
设置模型配置文件
访问 Model Zoo ,找到本次训练使用的模型:mmclassification\checkpoints\ 中,(自己新建一个文件夹)。config\base \model\flowers_resnet18.py ,对模型进行初始化。
model = dict ( type ='ImageClassifier' , backbone=dict ( type ='ResNet' , depth=18 , num_stages=4 , out_indices=(3 ,), style='pytorch' , init_cfg=dict ( type ='Pretrained' , checkpoint='.../mmclassification/checkpoints/resnet18_batch256_imagenet_20200708-34ab8f90.pth' , prefix='backbone' , ), frozen_stages=2 , ), neck=dict (type ='GlobalAveragePooling' ), head=dict ( type ='LinearClsHead' , num_classes=5 , in_channels=512 , loss=dict (type ='CrossEntropyLoss' , loss_weight=1.0 ), topk=(1 , 5 ), ) )
设置训练策略文件
可以新建也可以不新建,我直接用的 config\base \schedules\imagenet_bs256.py 。
optimizer = dict (type ='SGD' , lr=0.1 , momentum=0.9 , weight_decay=0.0001 ) optimizer_config = dict (grad_clip=None ) lr_config = dict (policy='step' , step=[30 , 60 , 90 ]) runner = dict (type ='EpochBasedRunner' , max_epochs=100 )
运行文件设置
在 config\base \default_runtime.py 中,设置多少批次打印日志,多少次迭代保存一次模型等等。
checkpoint_config = dict (interval=1 ) log_config = dict ( interval=25 , hooks=[ dict (type ='TextLoggerHook' ), ]) dist_params = dict (backend='nccl' ) log_level = 'INFO' load_from = None resume_from = None workflow = [('train' , 1 )] work_dir = 'work_dir'
设置模型主脚本
新建 configs\resnet\flower_resnet18_b32x8_imagenet.py ,将上述四个配置文件按顺序加入进来。
_base_ = [ '../_base_/models/flowers_resnet18.py' , '../_base_/datasets/flower_dataset.py' , '../_base_/schedules/imagenet_bs256.py' , '../_base_/default_runtime.py' ]
2.2 训练
目录 …\mmclassification\tools\ 中存放的是 mmcls 相关工具脚本,打开 tools\train.py ,这个就是启动训练的 Python 脚本。修改这两行:
parser.add_argument('config' , default="configs/resnet/flower_resnet18_b32x8_imagenet.py" , help ='train config file path' ) parser.add_argument('--work-dir' , default="train_result/flowers" , help ='the dir to save logs and models' )
在终端中输入
python tools/train.py configs/resnet/flower_resnet18_b32x8_imagenet.py
就开始了正式训练。结束之后,可以在 train_result\flowers\ 中找到训练的结果。其中 latest.pth 就是最终训练好的模型文件。
2.3 验证
测试的脚本在 tools\test.py ,这次我们直接在终端中输入
python tools/test.py configs/resnet/flower_resnet18_b32x8_imagenet.py train_result/flowers/latest.pth --out=val_res.json --metrics=accuracy
测试完成终端便会打印 top1 与 top5 的准确率,同时在 train_result\flowers\val_res.json 中还可以看到更加详细的测试情况。
总结
配置过程太艰辛了,尤其是像我这种没有任何基础的小白,有任何一个步骤出现了问题后面就都会出错。不过万事开头难,还是要脚踏实地一步一步的来。
附录




 wechat
wechat alipay
alipay

